პროგრამულ პროექტზე მუშაობისას, როგორც წესი, რამდენიმე გარემო გვაქვს. ერთი დეველოპმენტის, ერთი რეალური, შეიძლება კიდევ ერთი სატესტოც იყოს. თითოეულ მათგანში პროექტის კონფიგურაცია განსხვავებულია – მაგალითად, მონაცემთა ბაზის ან სერვისების მისამართები, API გასაღებები, პაროლები, სხვადასხვა ოფციები..
ჩვენი მიზანია, რომ სხვადასხვა გარემოსთვის სხვადასხვა კონფიგურაცია არსებობდეს, თანაც ისე, რომ ამისთვის გარემოს ყოველი შეცვლისას კოდის გადაკეთება, ip-ების ჩასწორება და რაღაცების დაკომენტარება არ დაგვჭირდეს. კოდს არ უნდა შევეხოთ. მოკლედ, მთავარი წესი ეს არის, რომ კოდი და კონფიგურაცია მკაცრად იყოს გაყოფილი ერთმანეთისგან.
ინტერნეტში კონფიგურაციის მართვის სხვადასხვა გზას შეხვდებით. პირველ რიგში, გააჩნია როგორი ინფრასტრუქტურა გაქვთ. ზოგიერთ პლატფორმას ან ფრეიმვორკს თავისი სპეციფიური მიდგომა აქვს რეალიზებული. ასევე, თუ პროექტი დიდ, განაწილებულ სისტემაშია დანერგილი, შეიძლება რაიმე მზა პროდუქტის გამოყენება იყოს მიზანშეწონილი, რომელიც მთელ ინფრასტრუქტურას აკონფიგურირებს ავტომატიზაციით (meta: Terraform, Puppet, Chef) . ამ პოსტში ვისაუბრებ შემთხვევაზე, როცა ერთ ან რამდენიმე (ცოტა) სერვერზე ვნერგავთ ჩვენს პროექტს.
კონფიგურაციის ბილდში ჩაყოლება
შეიძლება შეგხვდეთ ასეთი ვარიანტი, რომ პროექტის გამზადების დროს შესაბამის ბილდერ ხელსაწყოს ეთითება არგუმენტი, თუ რომელი გარემოსთვის დაბილდოს პროექტი. მერე ეს ბილდერი ნახულობს შესაბამის კონფიგურაციას და შესაბამის ფაილს სვამს ბილდში.
კარგ ვარიანტს ჰგავს, რადგან საბოლოოდ მხოლოდ ერთი გამზადებული არქივი გვაქვს და პირდაპირ გავუშვებთ ჩვენს სერვერსა და მის კლონებზე, მაგრამ რაღაც მინუსები აქვს ასეთ გზას:
ვინც კი დაბილდავს, მისთვის ხელმისაწვდომი უნდა იყოს რეალური გარემოს კონფიგურაცია
თუ კონფიგურაცია შეიცვალა, ან სხვა გარემოზე გვინდა ბილდის გაშვება, თავიდან გახდება გასაკეთებელი ან ხელით უნდა ჩავასწოროთ შიგნით კონფიგურაცია, თუ შესაძლებელია (გააჩნია როგორ მოხდა დაბილდვა).
კიდევ ხომ არ გაქვთ იდეა?
თუმცა ზოგ შემთხვევაში მე მგონი მეტი გზა არ არის, მაგალითად, კლიენტის მხარეს თუ არის პროგრამა – მობილურის აპლიკაციას როცა ვბილდავთ სხვადასხვა გარემოსთვის და მაინც ერთ ტელეფონზე ვუშვებთ ყველას, ან ჯავასკრიპტის პროექტი თუა, ბრაუზერში გასაშვები. ისე, ასეთ დროს პაროლები არც ინახება ხოლმე კონფიგურაციის ფაილში.
Environment ცვლადები
ეს გზა სულ უფრო პოპულარული ხდება და თანამედროვე ფრეიმვორკებში ხშირად შეხვდებით .env ფაილებს. ანუ, კონფიგურაცია გატანილია ოპერაციული სისტემის (ან კონტეინერის) environment ცვლადებში და განსხვავდება სხვადასხვა სერვერზე, აპლიკაციის ბილდი კი ყველგან ერთი და იგივეა.
ამ გზას თუ აირჩევთ, უნდა დარწმუნდეთ რომ აღნიშნული ცვლადები დაცულად არის შენახული სერვერზე OS-ის სხვა იუზერებისგან და რამე პროცესი არ ლოგავს სადმე. ასევე, რომ სხვა პროგრამა არ აწერს თავზე ან არ იყენებს (რადგან namespace-ები არ არის). როგორც ვიცი, ამის უზრუნველყოფა არ არის რთული, თუ სპეციალურად გამოყოფთ იუზერს თქვენი აპლიკაციისთვის. ან თუ რაიმე კონტეინერს იყენებთ (მაგ: Docker), იქაც იზოლირებულია env ცვლადები.
Env ცვლადები Node.js პროექტში
დეველოპმენტის პროცესი რომ მარტივი იყოს ამ მხრივ და სამუშაო მანქანებზე არ გვჭირდებოდეს env ცვლადების ხელით შევსება, არსებობს პატარა მოდული – dotenv, რომელიც პროექტში არსებულ .env ფაილს უყურებს და გარემოს ცვლადებს აინიციალიზირებს შესაბამისად.
.env ფაილი არ უნდა ინახებოდეს version control სისტემაში (.gitignore-ში არის ჩასამატებელი მაგალითად, თუ გიტს ვიყენებთ).
თუ რომელიმე ცვლადი უკვე არსებობს ოპერაციულში, მაშინ მას თავზე არ გადაეწერება .env ფაილის მონაცემები. როგორც წესი, dotenv მხოლოდ დეველოპმენტის გარემოსთვის არის და –save-dev პარამეტრით აყენებენ, თუმცა თუ რეალურ გარემოში ჩვეულებრივ სერვერზე ვდებთ პროექტს და რამე სპეციფიური გზით არ ხდება env ცვლადების კონფიგურირება (Docker, Heroku), პრინციპში, იქაც შეიძლება ამის გამოყენება. თუ არა და შესაბამისად დავსეტავთ ამ ცვლადებს და პროექტს .env ფაილის გარეშე დავნერგავთ.
რჩევა: env ცვლადებში ჯობია boolean ტიპის პარამეტრები არ შევინახოთ, რომ შემოწმებისას არარსებული პარამეტრი false-ად არ აღიქვას. ჯავასკრიპტს მაინც მუხთალი კონვერტაციები აქვს ტიპებს შორის 🙂
ამ პოსტში ყველაფერს ვერ შევეხე, იმედია აზრი გადმოვეცი 🙂 თქვენ როგორი მეთოდით აგვარებთ ხოლმე გარემოს კონფიგურირების თემას?
აქამდე Node.js არასდროს გამომიყენებია production გარემოში. ახლა ერთ-ერთ პროექტზე გადავწყვიტეთ მისი ცდა და მინდოდა პატარა კვლევები აქაც გამომექვეყნებინა. რომ გავუშვებთ, შედეგებზე და პრობლემებზე მერე დავწერ.
ზოგადად, ერთი ხელის მოსმით რთული გასაკეთებელია არჩევანი. იმის მიუხედავად, რომ ჯავასკრიპტზეც არც ისე ცოტა მიწერია, არასდროს ისე მყარად არ ვგრძნობ თავს, როგორც ჯავაში ან სხვა strongly typed ენაში. მექანიკური შეცდომების პოვნა საკმაოდ რთულია და არც ვიცი ხოლმე გადავაწყდები თუ არა როდესმე ტესტირებისას. შეცდომების მართვა (Error handling) ცალკე თავისტკივილია, რადგან შეიძლება ერთმა შეცდომამ მთელი სერვისი მოკლას. ბიბლიოთეკებს შორის არ არის მათი სტაბილური და ერთნაირი დამუშავება.
რაღაც მხრივ, node-ზე მაინც საყვარლად და კომპაქტურად იწერება სერვისები. არის პრეცედენტები, რომ დიდი კომპანიები გადავიდნენ node-ზე და ჯერჯერობით თავს ართმევენ (მაგ: Paypal). ჩვენს შემთხვევაში სოკეტები და ბრაუზერის ჯავასკრიპტი გვჭირდებოდა ინტენსიურად, ამიტომ ბოლოს ისევ node-ზე გავჩერდით.
მაშ ასე: ამოცანა არის REST API-ის გაკეთება.
ყველა პატარა კლასის თუ ფუნქციის გამო მოდულების ჩასმა არ მიყვარს, რადგან თითოეული dependency პოტენციური პრობლემაა. ყველაფრის ნოლიდან წერასაც არ ვაპირებ, ამიტომ ვცდილობ ბალანსი დავიცვა და მინიმალური რაოდენობის და ფუნქციების მოდულები გამოვიყენო.
მარშრუტებისთვის (routing) Restify-ზე შევჩერდი. ვებ საიტისთვის Express კარგიაო, მაგრამ სერვისების შემთხვევაში ბევრი რამე უფრო მარტივად არის, ამიტომ Restify საკმარისი ჩანს.
ტესტირებისთვის Mocha ავიღე. Mocha-ს ნებისმიერ assertion ბიბლიოთეკასთან შეუძლია მუშაობა. სტატიებში შეგხვდებათ ტუტორიალები – Should.js, Chai, expect.js, better-assert, unexpected.. მაგრამ ჩემი აზრით სულ ზედმეტია ეგ ყველაფერი. Node-ის ჩაშენებული assert მოდული მშვენივრად ართმევს თავს ყველაფერს, სხვა დანარჩენი კი უბრალოდ სიტყვების გადალაგება-გადმოლაგებაა.
ადრე ტესტებს საერთოდ არ ვწერდი. რაღაცნაირად უმეტესად ისეთ პროექტებზე ვხვდებოდი, რომელიც ან საიტი იყო ან წებო სხვადასხვა სისტემას შორის, ამიტომ ავტომატური ტესტირება არ გამოდიოდა. ახლა ვხვდები, რომ ტესტების გარეშე არ შემიძლია. შეიძლება იფიქროთ, რომ მეტ დროს გახარჯინებთ, მაგრამ პირიქით ძალიან ბევრ დროს ზოგავს და რუტინულ სამუშაოს გაცილებთ თავიდან. განსაკუთრებით მადლობას ეტყვით საკუთარ თავს ცვლილებების დროს (Regression testing), რადგან ერთი ბაგის გასწორების დროს ხშირად ბევრ ახალს ვაჩენთ სხვა ადგილებში.
ტესტების დამხმარედ არსებობს Code coverage ხელსაწყოები, რომელიც გვაჩვენებს ჩვენმა ტესტებმა კოდის რა ნაწილები დაფარა. ჯავასკრიპტზეც არის რამდენიმე, მე Instanbul-ზე შევჩერდი, რადგან ბევრი აქებდა.
Unit ტესტებისთვის ეს საკმარისია, თუმცა მე API-ის გატესტვაც მინდა და ამისთვის რამე პატარა http client მჭირდება. ცხადია, ცარიელი node-ითაც შეიძლება გაკეთება, მაგრამ მოდი კიდევ ერთ მოდულს დავამატებ სრული კომფორტისთვის – Supertest.
ამ პოსტში ყველაფერს ერთად ავამუშავებ. ოღონდ აუცილებლად უნდა აღვნიშნო, რომ ნამდვილი პროექტი უკეთ უნდა იყოს სტრუქტურირებული. მარშრუტები სხვა ფაილში, კონტროლერების ლოგიკა ცალკე, მოდელები და ბაზის ფენა ცალკე.. ამ მაგალითებში ერთ ადგილას არის მთელი სერვისი და სერვერის კონფიგურაცია-გაშვებაც.
პროექტის შექმნა
პირველ რიგში ინსტალირებული უნდა გქონდეთ Node.js და npm (პაკეტების მენეჯერი). ბრძანებების გაშვება ხდება ტერმინალში.
გადავიდეთ პროექტის საქაღალდეში და გავუშვათ ბრძანება
npm init
ეს რამდენიმე კითხვას დაგისვამთ და შედეგად შექმნის package.json ფაილს, რომელშიც მომავალში ჩვენი dependence-ები აღიწერება.
მოდულების ინსტალაცია
ისევ დავდგეთ პროექტის საქაღალდეში და გავუშვათ ბრძანება
npm install restify --save
შეიქმნება node_modules საქაღალდე და იქ გადმოიწერება მოდული. –save პარამეტრის შედეგად კი ჩვენს package.json-ში ჩაემატება.
ეს იმიტომ არის საჭირო, რომ მაგალითად node_modules საქაღალდეს პროექტს თან არ აყოლებენ ხოლმე, თუნდაც version control სისტემაში. ვისაც პროექტის გაშვება დასჭირდება, package.json ეყოფა, რომ საჭირო dependence-ები ჩამოტვირთოს.
ანალოგიურად გადმოვწეროთ Mocha, Instanbul და supertest:
ამ შემთხვევაში –save-dev-ს ვიყენებ, რადგან ეს ბიბლიოთეკები მხოლოდ დეველოპმენტის პროცესშია საჭირო და Production გარემოში მათი ინსტალაცია ზედმეტია.
სერვერის შექმნა და მარშრუტების გაწერა
შევქმნი მარტივ GET სერვისს, რომელსაც მისამართში გადმოეცემა name პარამეტრი და მისალმების ტექსტს აბრუნებს პასუხად. თუ კლიენტმა application/json ფორმატი მოითხოვა, json ობიექტად დააბრუნებს, სხვა შემთხვევაში კი ჩვეულებრივ ტექსტად.
index.js ფაილი
var restify = require('restify');
// შევქმნათ restify-ის სერვერი და აღვწეროთ მარშრუტები
var server = restify.createServer();
server.get('/hello/:name', sayHello);
server.head('/hello/:name', sayHello);
// ფუნქცია მოთხოვნის დასამუშავებლად
function sayHello(req, res, next) {
let content;
let name = req.params.name;
// თუ json-ს ითხოვს კლიენტი, json ობიექტი დაუბრუნდეს
// წინააღმდეგ შემთხვევაში ჩვეულებრივი ტექსტი
if (req.headers.accept.match(/json/i)) {
content = { hello: name };
// Restify ავტომატურად json-ს დააბრუნებს ასეთ დროს
} else {
content = 'hello ' + name;
res.header('Content-Type','text/plain');
}
res.send(content);
next();
}
// გავუშვათ სერვერი
server.listen(8080, function() {
console.log('%s listening at %s', server.name, server.url);
});
// ექსპორტი საჭიროა, რომ შემდეგ Mocha-დან მივწვდეთ სერვერს.
module.exports = server;
ტესტების შექმნა
პროექტის საქაღალდეში შევქმნათ საქაღალდე ‘test’ და მასში ჩავწეროთ ნებისმიერი სახელის ფაილი ტესტებისთვის. ასეთი ფაილები ნებისმიერი რაოდენობით შეიძლება გვქონდეს.
test/testHello.js
let request = require('supertest');
let server = require('../index');
let assert = require('assert');
describe('Hello', function () {
it('should say hello', done => {
request(server)
.get('/hello/elle')
.set('Accept', 'text/plain')
.expect('Content-type', 'text/plain')
.expect(200, "hello elle", done);
});
it('should say hello with json', done => {
request(server)
.get('/hello/elle')
.set('Accept', 'application/json')
.expect('Content-Type', /json/)
.expect(200, {
hello: "elle"
}, done);
});
});
შემდეგ package.json-ის scripts-ში გავწეროთ ტესტის გასაშვები ბრძანება:
"scripts": {
"test": "mocha"
}
შედეგად პროექტის საქაღალდიდან შეგვიძლია გავუშვათ ბრძანება
npm test
ასე გამოიყურება ტესტის შედეგი ჩემთან:
მოდი დავამატოთ code coverage. package.json-ში “test”: “mocha” შევცვალოთ შემდეგით: “test”: “nyc mocha” და ისევ გავუშვათ npm test.
ჩემს მაგალითზე კონსოლში გამოიტანა:
ახლა სრულად არის კოდი დაფარული ტესტებით. რაიმე ზედმეტ ფუნქციას ჩავამატებ და Uncovered Lines რაოდენობა გაიზრდება, თან ტერმინალში კარგად არ ჩანს შედეგი. html-ით რეპორტინგი გამოვიყენოთ. package.json-ში კვლავ შევცვალოთ კონფიგურაცია შემდეგით:
და კვლავ გავუშვათ npm test
პროექტის საქაღალდეში დაინახავთ, რომ შეიქმნა ახალი დირექტორია – coverage და მასში არის რეპორტის ფაილები. მაგალითად, ჩემი index.js ფაილის ანგარიში ასე გამოიყურება:
თუ ვერსიის კონტროლს იყენებთ, coverage და .nyc_output საქაღალდეები უმჯობესია .gitignore ფაილში დაამატოთ.
პროექტის საქაღალდეში არ გამოვაყოლე მოდულები. შეგიძლიათ გაუშვათ npm install ბრძანება პროექტის დირექტორიიდან და package.json-ის მიხედვით დააინსტალირებს საჭირო მოდულებს იმავე დირექტორიაში.
თუ სურვილი გაქვთ, რომ ხმოვანი წამკითხველი გამოიყენოთ ან სმენით დაატესტიროთ თქვენი საიტი, გთავაზობთ პატარა ინსტრუქციას:
NVDA (NonVisual Desktop Access) არის მსოფლიოში ეკრანის ერთ-ერთი ყველაზე გავრცელებული, უფასო მკითხველი ვინდოუს ოპერაციული სისტემისთვის. ის open-source პროექტია და ნებისმიერს შეუძლია მისი გადმოწერა ოფიციალური საიტიდან: www.nvaccess.org
საქართველოში უსინათლოების დიდი ნაწილი სწორედ ამ წამკითხველს ირჩევს კომპიუტერთან ურთიერთობისთვის.
ამჟამად NVDA-ს აქვს 43-ზე მეტი ენის მხარდაჭერა. მასში ჩადგმულია eSpeak ხმოვანი სინთეზატორი, რომელიც ქართული ენასაც მოიცავს, თუმცა ეს ქართული ვარიანტი ძალიან დასახვეწია. მართალია, მასზეც შეჩვეული აქვთ უკვე ყური, მაგრამ ბევრი ადამიანისთვის რთული აღსაქმელია. თუ თქვენ ოფიციალური საიტიდან გადმოწერეთ NVDA, შეიძლება ხელიც ჩაიქნიეთ ამ სინთეზატორის მოსმენისას.
საბედნიეროდ, უკვე არსებობს ქართული ხმოვანი სინთეზატორი, რომელიც გაცილებით კარგი მოსასმენია. მის შესახებ წინა პოსტებში და გამოსვლებში იყო საუბარი.
საქართველოს უსინათლოთა კავშირის საიტიდან შეგიძლიათ გადმოწეროთ პორტატული NVDA პროგრამა, რომელიც მართალია 2014 წლის არის და ბოლო წლების განახლებები არ აქვს, მაგრამ მას პლაგინის სახით მოჰყვება ქართული ხმოვანი სინთეზატორი GEOtts.
ინსტრუქცია:
1. ამოაარქივეთ გადმოწერილი ფაილი
2. გაუშვით nvda.exe
3. ქვევით Taskbar-ზე საათთან გაჩნდება NVDA-ს ლოგო. მასზე მაუსის მარჯვენა ღილაკის დაჭერით გავხსნათ პარამეტრების მენიუ:
4. სინთეზატორებში ავირჩიოთ GEOtts.
5. შესაძლებელია სურვილის მიხედვით დარეგულირდეს საუბრის სიჩქარე, ტონი და სხვა თვისებები. ამისთვის გახსენით მენიუ: პარამეტრები > ხმის პარამეტრები
ამ დროს ის უკვე უნდა ახმოვანებდეს თქვენს მოქმედებებს და გახსნილ ფანჯრებს. თუ ბრაუზერში გახსნით საიტს, ის დაიწყებს საიტის კითხვას. 2014 წლის შესაბამისად, კლავიატურით ინტერაქციის და shortcut-ებისთვის შეგიძლიათ იხილოთ ჩამონათვალი ამ გვერდზე: Keyboard Shortcuts for NVDA
აღნიშნული სტატია არის ამ გამოსვლის ტექსტური ვერსია
შესავალი
მოდით, აღიარებით დავიწყებ ჩემს მოხსენებას. 10 წელია, რაც აქტიურად ვმუშაობ პროგრამირების სფეროში, თუმცა რეალურად მხოლოდ შარშან ვნახე, თუ როგორ იყენებენ უსინათლო ადამიანები კომპიუტერს, ინტერნეტს, სოციალურ ქსელს და ელექტრონულ ფოსტას, 202-ე უსინათლოთა სკოლის პედაგოგი, ბატონი კახა ცხოვრებაშვილი მესაუბრა ამ ყველაფრის შესახებ. მაშინ დამაინტერესა როგორი მოსასმენი იყო ქართული ვებ-სივრცე. სახლში დაბრუნებისთანავე გადმოვწერე ეკრანის წამკითხველი პროგრამა და საიტების დათვალიერებას შევუდექი. სამწუხაროდ, ძალიან ცუდი სურათი დამხვდა.
ნამდვილად არ ვიტყვი, რომ ჩვენთან ჩამორჩენილია პროგრამირების სფერო. მსოფლიო დონის პროგრამისტები გვყავს ბევრი მიმართულებით და ისინი წარმატებით უწევენ კონკურენციას ნებისმიერს, უბრალოდ, ჩვენს ვებ-სივრცეში ნამდვილად არის რაღაცები გამოსასწორებელი.
დღეს ხომ ვები არ არის მხოლოდ კომუნიკაციის წყარო. ძალიან ბევრი გვერდითი ეფექტი აქვს, რაც თითოეულ ჩვენგანზე უზარმაზარ გავლენას ახდენს – პირადი ცხოვრება, თავის პოვნა და დამკვიდრება, თანამოაზრეების თუ სამსახურის პოვნა, ბიზნესის წამოწყება არა მხოლოდ ინტერნეტით, არამედ თვითონ ინტერნეტში. მოკლედ დამოუკიდებლობის ძალიან დიდ ხარისხს გვაძლევს, ხომ ასეა? სწორედ ეს იყო ჩემი მოტივაცია, რომ ცოტა მეტად გავრკვეულიყავი ამ პრობლემაში. დასანანია, რომ დღეს საქართველოში ათეულობით ათასი ადამიანია, ვისთვისაც ეს სიკეთეები ხელმისაწვდომი არ არის.
რა იწვევს ასეთ სურათს? ათი წლის განმავლობაში რატომ ვერ დავეწიეთ სხვა ქვეყნებს? ჩემი აზრით, მნიშვნელოვანია პრობლემის სათავის ძებნა. რამდენიმე სავარაუდო მიზეზი მაქვს. მეც ძალიან შემეცვალა შეხედულება ამ მიზეზებზე და ამიტომ ვეცდები, რომ რამდენიმე მითი მაინც გავაქარწყლო.
შეიძლება ვფიქრობთ, რომ:
1. ქართული ენისთვის არ არსებობს საჭირო ტექნოლოგიები
შორეულ წარსულში ეს ასეც იყო, მაგრამ დღეს ეკრანის მკითხველში არის ქართული ენა. ასევე არსებობს ქართული ხმოვანი სინთეზატორიც.
ზოგიერთი ადამიანისთვის შეიძლება დასახვეწია სხვადასხვა კუთხით, შეიძლება ინტონაციები, ხმები გასაუმჯობესებელია, მაგრამ ფაქტია, რომ რეალურად დღეს შესაძლებელია ამ ყველაფრის გამოყენება და საიტები რომ იყოს შესაბამისად გამართული, დღესვე შეძლებენ უსინათლო ადამიანები მათგან ინფორმაციის მიღებას.
2. ადაპტირება მნიშვნელოვნად ზრდის პროექტის ბიუჯეტს, საჭიროა გაცილებით მეტი რესურსი.
ზოგიერთ შემთხვევაში, თუ ინტერაქციებით დატვირთულ ვებ სისტემას გვაქვს საქმე ან დიზაინი არანაირად არ ითვალისწინებს UX-ს, მართლაც მეტი რესურსია საჭირო, თუმცა ძალიან ბევრი საიტისთვის, რომელიც თავის მხრივ სტანდარტების მიხედვით და სემანტიკური სტრუქტურით იყო შექმნილი, ადაპტირებას შეიძლება მხოლოდ 1-2 დღის სამუშაო დასჭირდეს.
3. არ გვაქვს შესაფერისი კვალიფიკაცია / ძალიან რთულია
კიდევ ერთხელ აღვნიშნავ, რომ როდესაც დაცულია ვებ აპლიკაციის სტანდარტები, იქიდან პატარა ნაბიჯია დარჩენილი ადაპტირებამდე. ხოლო თავის მხრივ ადაპტირების სტანდარტების ძირითად ნაწილში გარკვევა რამდენიმე დღეში შეიძლება.
4. ვერ გავაკეთებთ ტესტირებას
ნამდვილად კარგი იქნება, თუ იმ ადამიანების ჯგუფი გააკეთებს ტესტირებას, ვინც რეალურად გამუდმებით იყენებს ეკრანის მკითხველს, თუმცა ჩვენ თვითონ შეგვიძლია მარტივად ჩავწეროთ უფასო, პატარა წამკითხველი პროგრამა, გამოვრთოთ მონიტორი და ჩვეულებრივ გამოვიყენოთ საიტი კლავიატურით და სმენით.
5. “ამის დრო არ არის, ისედაც ვერ ვასწრებთ დასრულებას”
ეს ალბათ ყველაზე გავრცელებული და საფუძვლიანი მიზეზია. უბრალოდ კარგია, როცა ბიზნესისთვის ადაპტირება პრიორიტეტულია, რაც ყოველთვის ვერ იქნება, მესმის. თუმცა არც ყველა პროექტია ბიზნესთან დაკავშირებული.
“კალდრა”
სანამ ტექნიკურ დეტალებზე გადავალ, მსურს, რომ პატარა ექსპერიმენტულ პროექტზე მოგიყვეთ. მე თვითონ ძალიან დიდი ხანია რაც საკუთარი ბლოგი მაქვს და რაღაცნაირი საყვარელი პატარა პირადი სივრცეა ჩემთვის. უფრო ავტორისთვის არსებობს, ვიდრე მკითხველისთვის. რაც არ უნდა უცნაური იყოს, მაგ ბლოგის წყალობით ვიპოვე არაერთი კარგი მეგობარი და სამსახურის შეთავაზებებიც კი. ამიტომ ვიფიქრე, კარგი იქნებოდა არსებობდეს მსგავსი შესაძლებლობა, სადაც ნებისმიერ თემაზე შეიძლება გამოთქვას აზრი ადამიანმა, წეროს სტატიები, ა.შ.
არის მსგავსი სისტემები, მაგალითად ამერიკული WordPress. თვითონ WordPress ადაპტირებულია წამკითხველებისთვის. არსებობს ინტერფეისის ქართული თარგმანიც, თუმცა ამ სისტემის გამოყენება დამოუკიდებლად არ არის მარტივი. რეგისტრაციას სჭირდება ეტაპები, ელექტრონული ფოსტის აქტიურად გამოყენება; ინტერფეისი არის ძალიან მრავალფეროვანი და ადმინისტრატორის პანელს ძალიან ბევრი ფუნქციები აქვს, ამიტომ ბოლოს გადავწყვიტე ბლოგების ძალიან მინიმალისტური, პატარა სისტემა შემექმნა. ვეცადე, რომ ბოლომდე შემემცირებინა ოპერაციები, მენიუები, ღილაკები, გამემარტივებინა ფორმები.. იქ ადამიანი უბრალოდ შევა, დაწერს სტატიას და ღილაკის ერთი დაჭერით გამოაქვეყნებს.
მოკლედ მიმოვიხილავ:
ადამიანი რეგისტრირდება
ქმნის ბლოგს, რომლის მისამართიც გახდება <შერჩეული სახელი>.kaldra.ge
წერს სტატიებს
კომენტარების საშუალებით ეხმაურება სხვა სტატიებს
გზავნის შეტყობინებებს სხვადასხვა მომხმარებელთან
შეუძლია ნახოს სტატისტიკა მისი ბლოგის ან სტატიის სტუმრების შესახებ
შეუძლია შეაგროვოს საყვარელი ბლოგები ერთად
სულ ეს არის.
შეიძლება ეს არ იყოს სტანდარტებით ადაპტირებული სისტემის იდეალური მაგალითი. მე სპეციალურადაც კი მოვაცილე ზოგიერთი ტეგი, რომელიც ყურში ზედმეტად მხვდებოდა და ძირითადად ორიენტირებული ვიყავი პრაქტიკულ გამოცდაზე. ზუსტად ამიტომ ზოგიერთი ფრაგმენტი ჩვეულებრივი საიტისგან განსხვავებულად გავაკეთე. უბრალოდ მაგალითისთვის მინდა მოვიყვანო რამდენიმე, რადგან შეიძლება სხვამ უკეთესი გადაწყვეტა იპოვოს.
1. თავის დაზღვევა შევსებული ფორმების დაკარგვისგან
შევამჩნიე, რომ მხოლოდ მოსმენით ტექსტის წერის და შემოწმების დროს შედარებით მეტი დრო მჭირდებოდა, ასევე არ მინდოდა რომ შევსებული ფორმის გაგზავნისას ინტერნეტის გათიშვის ან რაიმე შეცდომის გამო დამკარგოდა ნაწერი, ამიტომ ყველა ასეთი გვერდის შეცვლამდე წინასწარ ვგზავნი სერვერზე მონაცემებს და მხოლოდ წარმატებული პასუხის შემდეგ ვცვლი გვერდს.
2. ოპერაციის პროცესში მიმდინარე სტატუსის გაგება
როდესაც საიტს გაუგრძელდება სერვერის პასუხის ლოდინი რაიმე ოპერაციისთვის, ზოგჯერ გაურკვეველია მომხმარებლისთვის რა ხდება, ამიტომ დავამატე პატარა სტატუსები. მაგალითად, თუ ფორმის შევსების შემდეგ მომხმარებელი მეორედ ეცდება მონაცემების გაგზავნას, ხმოვან შეტყობინებას მიიღებს, რომ ჯერ კიდევ მიმდინარეობს შენახვის ოპერაცია.
3. კოდირებებს შორის კონვერტაცია
გამორთული მონიტორით ზოგჯერ მავიწყდებოდა, თუ რომელ ენაზეა გადართული კლავიატურა. განსაკუთრებით ძნელი დასადგენია მიზეზი, როდესაც არასწორი პაროლის შეცდომა ხდება ან ძებნის შედეგები განსხვავებულია. ამიტომ გადავწყვიტე, რომ რამდენიმე ფორმაზე მონაცემები დამუშავდეს ორივე კოდირებაში. ეს ცოტა არასტანდარტული გზაა, თუმცა ჩემი აზრით ასე ჯობდა საიტის გამოყენებისას.
4. გვერდების და ფორმების მოკლე აღწერა
გვერდის შეცვლისას კარგია, როდესაც მომხმარებელმა იცის სად არის, ამიტომ ყველა გვერდი იწყება სათაურით ან დასაწყისში დამატებული აქვს პატარა აღწერა. მაგალითად ფოტოზე:
“მიმოწერა მომხმარებელთან ბაში აჩუკი”
“ამ გვერდზე შეტყობინებები დალაგებულია თარიღის კლებადობით”
როგორ იღებს მკითხველი ინფორმაციას ოპერაციული სისტემიდან და ბრაუზერიდან?
შეიძლება გაგვიჩნდეს კითხვა, თუ საიდან აქვს წვდომა ამდენ ინფორმაციაზე ეკრანის მკითხველს და ხომ არ არღვევს უსაფრთხოებას. ამის პასუხია: Accessibility API.
ოპერაციულ სისტემას და ბრაუზერებსაც გააჩნიათ სპეციალური API, რომლითაც ეკრანის მკითხველს უზიარებენ ინფორმაციას.
მოდით, შევხედოთ რა ხდება ბრაუზერში:
HTML სტრუქტურა
DOM ხე (დოკუმენტის ობიექტური მოდელი)
ზოგადად, გვერდის დამუშავებისას html ელემენტებსა და მათ მდგომარეობაზე დაყრდნობით ბრაუზერი აგებს დოკუმენტის ობიექტურ მოდელს – DOM ხეს და შემდეგ არენდერებს მას.
ამასთანავე, იმავე ინფორმაციაზე დაყრდნობით ის აგებს მეორე ხესაც – Accessibility tree.
როდესაც DOM ხეში დინამიურად ვცვლით ელემენტების მდებარეობას ან მდგომარეობას, ანალოგიური ცვლილებები ცოცხალ (live) რეჟიმში აისახება მეორე ხეზეც.
სწორედ ამ ხეზე აქვს წვდომა ეკრანის მკითხველს. ამის წყალობით ის არა მხოლოდ სერვერიდან დაბრუნებულ html-ს, არამედ ბრაუზერში დინამიურად შექმნილ სტრუქტურასაც კითხულობს. შედეგად კარგად მუშაობს დღესდღეობით პოპულარულ ჯავასკრიპტის ფრეიმვორკებთან, სადაც აპლიკაციის ლოგიკა სრულად ბრაუზერის მხარეს გადმოტანილი და ჯავასკრიპტით იქმნება გვერდები, მაგალითად Angular, React, ა.შ.
(ბრაუზერში DOM ხის ნახვა და დათვალიერება შესაძლებელია მისი ინსპექტორის საშუალებით. ასევე შეგვიძლია ვნახოთ მეორე ხე, მაგალითად ქრომში ის არის chrome://accessibility გვერდზე)
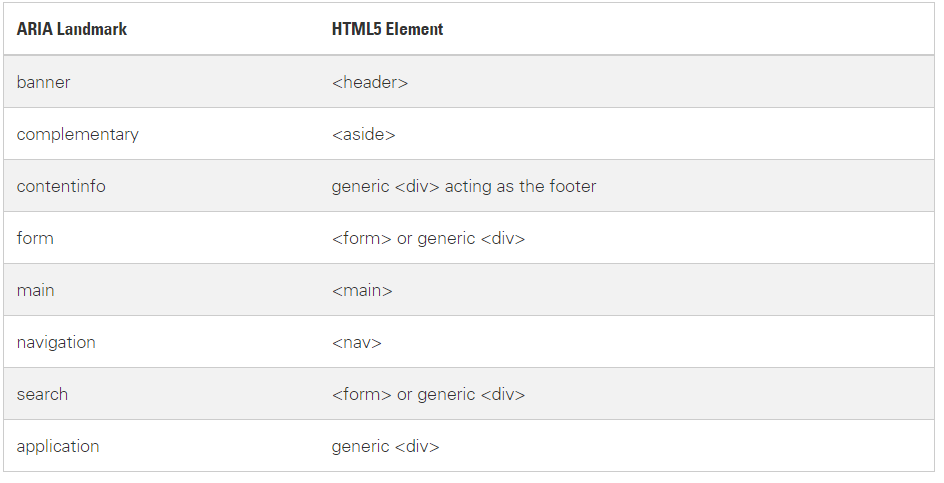
WAI-ARIA (Web Accessibility Initiative – Accessible Rich Internet Applications)
ადრე, HTML 4-ის დროს, ელემენტები კარგად ვერ აღწერდნენ საკუთარ დანიშნულებას და მდგომარეობას. ამიტომ WAI-ARIA სტანდარტის ფარგლებში შემოღებული იქნა დამატებითი სემანტიკა და მეტამონაცემები, რომლებიც ამ ამოცანას ასრულებდნენ. ბრაუზერიც სწორად ამ ინფორმაციით სარგებლობს, როდესაც Accessibility ხეს აგებს.
მაგალითად:
<div role=”navigation”> role ატრიბუტი მიანიშნებს, რომ ეს ელემენტი განკუთვნილია ნავიგაციისთვის.
იგივე ჩანაწერი html5-ით:<nav></nav>აუცილებლად უნდა აღინიშნოს, რომ html5 სტანდარტში მნიშვნელოვნად გაუმჯობესდა სემანტიკა და ისედაც შესაძლებელია ელემენტების უკეთ აღწერა. უფრო მეტიც, არაერთი ექსპერტის აზრით და მეც სრულებით ვეთანხმები, რომ რამდენადაც შეიძლება, იმდენად უნდა შემცირდეს ARIA ატრიბუტების გამოყენება და მხოლოდ მაშინ გამოვიყენოთ, როცა მისი ანალოგი არ არის html5-ში.
სრულად ვერ ავიცილებთ თავიდან. მაგალითად, ავიღოთ ელემენტის დამალვა, რაც ძალიან ხშირად არის საჭირო. hidden ატრიბუტი, ისევე როგორც “display: none” სრულად დამალავს ელემენტს და accessibility ხიდანაც ამოიღებს. მაგრამ, თუ გვსურს, რომ ელემენტი ჩანდეს ვიზუალურად და მხოლოდ მკითხველისთვის იყოს დამალული, მაშინ დაგვჭირდება aria-hidden=”true” ატრიბუტის გამოყენება.
თუ გვსურს, რომ პირიქით, ვიზუალურად დავმალოთ და მკითხველისთვის ხელმისაწვდომი დარჩეს, მაშინ უბრალოდ როგორმე შორს უნდა გავწიოთ კონტენტი ხილული არედან. მაგალითად, კალდრაზე ასეთ css კოდს ვიყენებ:
ასეთი სტილით ელემენტი ისევ საიტზეა, მკითხველიც ჩვეულებრივ კითხულობს, უბრალოდ იმდენად შორს არის გაწეული, რომ თვალით ვერ ვხედავთ.
ძირითადი პრინციპები ადაპტირებისთვის
ხელმისაწვდომობის სტანდარტების სრულყოფილად მიყოლა ცხადია კარგია, თუმცა სიმარტივისთვის გამოვყავი ძირითადი პრინციპები. ვთვლი, რომ მინიმუმ მათი დაცვით (რაც სირთულეს არ წარმოადგენს), ქართული ვებ-სივრცის უკვე ძალიან დიდ ნაწილს დავფარავთ და ეკრანის მკითხველისთვის კითხვადს გავხდით.
1. სემანტიკურად გამართული საიტი
ვებ აპლიკაციის html კოდი უნდა იყოს სემანტიკურად გამართული. ეს არა მხოლოდ მკითხველისთვის არის კარგი. აქამდე, თუ ვინმე იკითხავდა მიზეზს, ჩვენ ვპასუხობდით, რომ საძიებო სისტემებმა კარგად შეძლონ გვერდის დამუშავება. ჩემი აზრით, ეკრანის მკითხველი კიდევ უფრო კარგი მიზეზია ამისთვის.
რას ნიშნავს სემანტიკურად გამართული? მოკლედ რომ ვთქვათ, ჩვენ შეგვიძლია მთელი ჩვენი html სტრუქტურა <div> ელემენტებით აღვწეროთ და გარეგნულად ნებისმიერი ვიზუალი გავუკეთოთ, მაგრამ მათ არ ექნებათ არანაირი სემანტიკური ინფორმაცია. პროგრამულად ვერ მივხვდებით, რომელია ნავიგაციის ბლოკი, რომელი სათაურის, რომელი მთავარი ტექსტის, ა.შ. ამის ნაცვლად, შეგვიძლია გამოვიყენოთ
<header>,<nav>,<article>და სხვა კონკრეტული ელემენტები, რომლებიც უკვე უკეთ წარმოაჩენენ გვერდის სტრუქტურას – არა თვალისთვის, არამედ მკითხველი პროგრამისთვის.
2. კარგი ნავიგაცია და აღწერილი ბმულები
კარგი ნავიგაცია ზოგადად ნებისმიერ საიტს სჭირდება, არა მხოლოდ ადაპტირებულს. ეს UX-ის (User Experience) ამოცანაა. როდესაც საიტი იქმნება, ერთ-ერთი მთავარი წესია, რომ ნავიგაცია იყოს მოსახერხებელი და გვერდები მარტივად იყოს წვდომადი.
კვლევისას შემხვდა რამდენიმე საიტი, რომელიც საკმაოდ კარგად იკითხებოდა მკითხველით. უბრალოდ იმხელა ნავიგაცია ჰქონდათ, რომ 20-30 ღილაკი უნდა გადამევლო მთავარ კონტენტამდე მისაღწევად. თუ ასეთი დიდი მენიუ გვაქვს, შესაძლებელია რომ ეკრანის მკითხველისთვის მისი სტრუქტურა გავამარტივოთ ან შესაძლებელი იყოს მათზე გადახტომა და მომხმარებელს არ ვაიძულოთ ყოველი გვერდის შეცვლაზე ათეულობით ღილაკის გადავლა.
ასევე აღსანიშნავია, რომ მომხმარებელმა მთელ საიტზე არსებული ბმულები შეიძლება ერთიანად, კონტექსტიდან ამოღებული გაიაროს. ამიტომ უმჯობესია რომ ისინი კარგად იყოს აღწერილი და ბმულის სათაური არ იყოს “აქ დააჭირეთ”. თუ თვითონ <a> ტეგის შიგნით შეუძლებელია, მაშინ title ატრიბუტით შეგვიძლია მივუთითოთ აღწერა.
3. ორიენტირები
ორიენტირები ძალიან მნიშვნელოვანია. საიტზე შეგვიძლია გამოვყოთ სხვადასხვა სექცია და განვსაზღვროთ, თუ რა არის იმ ნაწილში. მაგალითად ცალკე შეიძლება იყოს გვერდის ზედა-თავი, ცალკე ნავიგაცია, ცალკე მთავარი შიგთავსი. ასეთ ბლოკებს შეგვიძლია გავუკეთოთ ორიენტირები და მომხმარებელს საშუალება ექნება მთლიან ბლოკებს შორის იმოძრაოს. ეს კარგი გადაწყვეტაა ზევით ნახსენები პრობლემისთვისაც, სადაც ნავიგაცია ძალიან ბევრ ბმულს შეიცავდა და მომხმარებელს არ შეეძლო საიტის სხვა ნაწილზე გადახტომა.
ორიენტირის განსაზღვრა შესაძლებელია როგორც ARIA ატრიბუტით, ისე html5 ტეგებით.
4. უსასრულო სქროლი
საუბარია ისეთ გვერდზე, რომელიც არასდროს სრულდება. როცა კი მომხმარებელი ქვევით ჩასქროლავს, დინამიურად იტვირთება გვერდის გაგრძელდება. მაგალითად, წარმოიდგინეთ facebook.
ცხადია, ასეთ გვერდსაც კითხულობს მკითხველი და დინამიურად შეცვლილი ან დამატებული შიგთავსის წაკითხვაც შეუძლია, მაგრამ ბევრისთვის ასეთი გვერდის მოსმენა ძალიან მოუხერხებელია. ძნელია გვერდზე ორიენტაცია, როდესაც არ იცი სად მთავრდება.
5. საიტის დამალული შიგთავსი და ფოტოები
თუ საიტზე გვაქვს ბანერები, სლაიდები, ისეთი ზედმეტი ელემენტები, რომლის მკითხველით წაკითხვასაც აზრი არ აქვს, უმჯობესია დავმალოთ. მათი მოსმენა დამღლელია. ისინი შეგვიძლია მარტივად ამოვიღოთ მკითხველისგან aria-hidden ატრიბუტის გამოყენებით. ანალოგიურად დავმალოთ დეკორატიული ხასიათის ფოტოებიც. დანარჩენ ფოტოებს კი გავუკეთოთ შესაბამისი აღწერა ატრიბუტში.
6. ორი ინტერფეისი
არის კიდევ ერთი გზა საიტის წაკითხვის გასამარტივებლად. თუ გვაქვს რთული ინტერფეისი და არ გვსურს მისი მნიშვნელოვნად გადაკეთება ადაპტირების გამო, წამკითხველისთვის შეგვიძლია შემოვიღოთ მეორე ინტერფეისი. ანუ ვიზუალურად გამოჩენილი ნაწილი მოქცეული იყოს aria-hidden ატრიბუტში მკითხველისგან დასამალად, ხოლო ადამიანის თვალისგან მოშორებით იყოს წამკითხველზე მორგებული მეორე ინტერფეისი. შიგთავსი შეგვიძლია ჯავასკრიპტით გადავაკოპიროთ მეორე ინტერფეისის ელემენტებში გვერდის ჩატვირთვის დროს, ან შეგვიძლია უბრალოდ სერვერის მხარესვე გამზადებული გვერდი დავაგენერიროთ დუბლირებული შიგთავსებით.
7. iframe პრობლემა
iframe-ებს ხშირად ვიყენებთ საიტზე, განსაკუთრებით, როდესაც სოციალური ქსელების ფუნქციების ინტეგრაცია გვჭირდება. ეკრანის წამკითხველი ჩვეულებრივ წაიკითხავს ასეთ გვერდს. როდესაც iframe შეხვდება, მის შიგთავსსაც ჩვეულებრივ წაიკითხავს, მაგრამ დასრულების შემდეგ ის გვერდის თავში გადახტება. ზუსტად არ ვიცი, რა იწვევს ასეთ საქციელს, მაგრამ მნიშვნელოვანია ასეთი შემთხვევის არიდება. წინააღმდეგ შემთხვევაში მომხმარებელი მუდმივად გაიჭედება iframe-ის ადგილას და მის ქვემოთ ვერასდროს ჩამოვა. პრობლემის გადასაჭრელად შეგვიძლია ორიენტირები გამოვიყენოთ. შედეგად მომხმარებელი შეძლებს პირდაპირ შემდეგ სექციაში გადავიდეს.
დასკვნა
კიდევ ერთხელ მსურს გავამახვილო ყურადღება, რომ შეიძლება ჯერჯერობით სრულად ვერ მივყვეთ სტანდარტებს სხვადასხვა პრობლემის თუ დროის ფაქტორის გამო, მაგრამ ძირითადი პრინციპები მაინც რომ დავიცვათ, მჯერა, რომ ქართული ვებ-სივრცის ძალიან დიდი ნაწილი გახდება ხელმისაწვდომი.
ზოგადად, ამ პრობლემის გადასაჭრელად ორი გზა გამოიკვეთა. ერთი არის ხმოვანი ვებ აპლიკაციების შექმნა, სადაც თავად საიტზეა განლაგებული აუდიო ფაილები ან სერვერი აგენერირებს მათ მოთხოვნისას. ასეთი საიტის მაგალითია voice.police.ge
მეორე გზაა, რომ ვებ აპლიკაცია სრულიად ჩვეულებრივი იყოს, უბრალოდ – წამკითხველი პროგრამისთვის სემანტიკურად გამართული.
ორივე გზას აქვს დადებითი და უარყოფითი მხარე. პირველი ვარიანტი გაცილებით რთული გასაკეთებელია, ამის გამო ხშირად შეზღუდულია ფუნქციონალი. მაგალითად ზემოთ ნახსენებ საიტზე მომხმარებელს მხოლოდ მომდევნო ან წინა ელემენტზე გადასვლის შესაძლებლობა აქვს. სამაგიეროდ, წამკითხველი პროგრამა არ სჭირდება.
მეორე გზის სასარგებლოდ უნდა ითქვას, რომ უსინათლო მომხმარებელი მხოლოდ კონკრეტულ საიტზე არ შედის, არამედ ჩვეულებრივ იყენებს ოპერაციულ სისტემას, ხსნის ბრაუზერს და უსმენს სხვადასხვა საიტს. ანუ, მას უკვე აქვს ჩართული წამკითხველი პროგრამა, რომელიც OS-ის ოპერაციებს ჩვეულებრივ ახმოვანებს. ხოლო ბრაუზერის Accessibility API-ის წყალობით ის უსმენს არა რამდენიმე კონკრეტულ საიტს, არამედ ნებისმიერს. მთავარია, ცოტა გამართულად ეწეროს. წამკითხველი პროგრამა ნავიგაციის და ინტერაქციის კარგ საშუალებას იძლევა.
კარგია, როდესაც ორივე ვარიანტია რეალიზებული. თუმცა თუ ერთი უნდა ავირჩიოთ, მე მეორე გზას ვემხრობი და მიმაჩნია, რომ სტანდარტული ვარიანტი ყოველთვის მომგებიანია. არ არის საჭირო ყველა საიტზე მოვიგონოთ ინტერაქციის ახალი ინტერფეისი და ვაიძულოთ მომხმარებელს, გაერკვიოს.
არაერთხელ შემხვედრია მოსაზრება, რომ ჩვენი მთავრობა უნდა ზრუნავდეს ქართული ვების ხელმისაწვდომობაზე, უნდა არსებობდეს სპეციალური ჯგუფები, ა.შ. ეს ნამდვილად კარგი იქნება, თუმცა მე ვფიქრობ რომ დღეს ჩვენ, პროგრამისტები ვქნით ვებს საკუთარი ხელით, ჩვენ ვირჩევთ ტექნოლოგიებს, ვაწესებთ ტრენდებს, ვასწავლით ერთმანეთს სიახლეებს. ამიტომ ჩვენს ხელთ არანაკლები ძალაა ამ პრობლემის გამოსასწორებლად.
დანართი: წამკითხველის ინსტრუქცია
თუ სურვილი გაქვთ, რომ ხმოვანი წამკითხველი გამოიყენოთ ან სმენით დაატესტიროთ თქვენი საიტი, გთავაზობთ პატარა ინსტრუქციას:
NVDA (NonVisual Desktop Access) არის მსოფლიოში ეკრანის ერთ-ერთი ყველაზე გავრცელებული, უფასო მკითხველი ვინდოუს ოპერაციული სისტემისთვის. ის open-source პროექტია და ნებისმიერს შეუძლია მისი გადმოწერა ოფიციალური საიტიდან: www.nvaccess.org
საქართველოში უსინათლოების დიდი ნაწილი სწორედ ამ წამკითხველს ირჩევს კომპიუტერთან ურთიერთობისთვის.
ამჟამად NVDA-ს აქვს 43-ზე მეტი ენის მხარდაჭერა. მასში ჩადგმულია eSpeak ხმოვანი სინთეზატორი, რომელიც ქართული ენასაც მოიცავს, თუმცა ეს ქართული ვარიანტი ძალიან დასახვეწია. მართალია, მასზეც შეჩვეული აქვთ უკვე ყური, მაგრამ ბევრი ადამიანისთვის რთული აღსაქმელია. თუ თქვენ ოფიციალური საიტიდან გადმოწერეთ NVDA, შეიძლება ხელიც ჩაიქნიეთ ამ სინთეზატორის მოსმენისას.
საბედნიეროდ, უკვე არსებობს ქართული ხმოვანი სინთეზატორი, რომელიც გაცილებით კარგი მოსასმენია. მის შესახებ წინა პოსტებში და გამოსვლებში იყო საუბარი.
საქართველოს უსინათლოთა კავშირის საიტიდან შეგიძლიათ გადმოწეროთ პორტატული NVDA პროგრამა, რომელიც მართალია 2014 წლის არის და ბოლო წლების განახლებები არ აქვს, მაგრამ მას პლაგინის სახით მოჰყვება ქართული ხმოვანი სინთეზატორი GEOtts.
ინსტრუქცია:
1. ამოაარქივეთ გადმოწერილი ფაილი
2. გაუშვით nvda.exe
3. ქვევით Taskbar-ზე საათთან გაჩნდება NVDA-ს ლოგო. მასზე მაუსის მარჯვენა ღილაკის დაჭერით გავხსნათ პარამეტრების მენიუ:
4. სინთეზატორებში ავირჩიოთ GEOtts.
5. შესაძლებელია სურვილის მიხედვით დარეგულირდეს საუბრის სიჩქარე, ტონი და სხვა თვისებები. ამისთვის გახსენით მენიუ: პარამეტრები > ხმის პარამეტრები
ამ დროს ის უკვე უნდა ახმოვანებდეს თქვენს მოქმედებებს და გახსნილ ფანჯრებს. თუ ბრაუზერში გახსნით საიტს, ის დაიწყებს საიტის კითხვას. 2014 წლის შესაბამისად, კლავიატურით ინტერაქციის და shortcut-ებისთვის შეგიძლიათ იხილოთ ჩამონათვალი ამ გვერდზე: Keyboard Shortcuts for NVDA
წარმოგიდგენთ ერთ ექსპერიმენტულ პროექტს: “კალდრა” არის ბლოგების მინიმალისტური პლატფორმა, რომელიც ადაპტირებულია ეკრანის წამკითხველებისთვის. შედეგად უსინათლო მომხმარებელს სრულიად დამოუკიდებლად შეუძლია მისი გამოყენება.
kaldra.ge საიტზე შესაძლებელია:
• მომხმარებლის რეგისტრაცია
• საკუთარი საიტის – ბლოგის შექმნა, რომელსაც ექნება მისამართი <შერჩეული სახელი>.kaldra.ge
• სტატიების გამოქვეყნება
• საკუთარ ბლოგსა და სტატიებზე სტუმრების სტატისტიკის ნახვა
• სტატიებზე გამოხმაურება
• სხვა მომხმარებლებთან მიმოწერა
• საყვარელი ბლოგების შეგროვება
• სტატიების ძიება
თუ დაგაინტერესებთ, ვიდეოებში ნახავთ, თუ როგორ იყენებენ უსინათლო მომხმარებლები კომპიუტერს და ინტერნეტს; ასევე მოუსმენთ ქართულ ხმოვან სინთეზატორს; მე კი ვსაუბრობ იმ ტექნიკური პრინციპების შესახებ, რომლის დაცვითაც მარტივად შეიძლება ქართული ვებ სივცრის ადაპტირება.
“კალდრამ” პირველადი ტესტირება უკვე გაიარა, ახლა კი საიტების შემქმენელებს ელის 🙂 თუ იცნობთ ვინმეს, ვინც თავად იყენებს ეკრანის მკითხველს ან უბრალოდ სურს, რომ მისი სტატიები ხელმისაწვდომი იყოს უსინათლო პირებისთვის, გთხოვთ, გაუზიარეთ ინფორმაცია ამ პროექტის შესახებ.
შენიშვნებს და რჩევებს სიამოვნებით მივიღებ და ვეცდები გავაუმჯობესო პლატფორმა.
ამჟამად, ვეცადე რომ არ გამერთულებინა სისტემა და რაც შეიძლება ნაკლები ოპერაციები ყოფილიყო საჭირო ბლოგისა და სტატიების შექმნისთვის.
კალდრასთვის Facebook გვერდი შევქმენი, სადაც ამ საკითხებთან დაკავშირებულ სიახლეებს გამოვაქვეყნებ ხოლმე.